- Published on
Claude Code 源码学习
- Authors

- Name
- Stone
Claude Code 源码学习
参考文档:
- https://www.ibm.com/think/topics/ai-agents
- https://github.com/6551Team/claude-code-design-guide/
- https://x.com/HiTw93/status/2032091246588518683

常用命令
| 命令 | 作用 |
|---|---|
/help | 显示帮助 |
/clear | 清空对话历史 |
/compact | 压缩对话上下文 |
/cost | 显示本次对话的 token 消耗和费用 |
/config | 查看或修改配置 |
/model | 切换模型 |
/commit | 生成 git commit 信息并提交 |
/exit | 退出 |
Unix 哲学的核心是三条原则:
- 单一职责:每个程序只做一件事,并把它做好
- 组合性:程序之间通过标准接口(文本流)协作
- 透明性:程序的行为可预测、可观察
实际上,最开始我们接触到的 ChatGPT,并不能算作 AI Agent,只能算作聪明的文本生成器,工作模式就是 输入文本 → [LLM] → 输出文本
但当时的它只能进行文本的生成,对于任何的操作,都是无法执行的,直到 2023 年的时候,OpenAI 引入了 Function Calling,cc 的母公司 Anthropic 引入了 Tool Use,AI 才开始从一问一答的聊天机器人进行转向,逐步变为现在的能执行各种操作的 AI Agent
比如过去我们问 AI,今天天气怎么样?LLM 只是在基于之前的训练语料去预测他要回答的内容,并不能真正的知道今天的天气,但是有了 Function Calling 和 Tool Use,AI 开始直接调用对应的天气 API,可以执行对应的工具,能够真正的去获取真实的天气情况,从瞎猜到了会用工具
如果要更直白地理解 Agent,那么一个 Agent 就必须要有以下的功能:
- 感知(Perception)
- 获取信息(用户输入、环境数据、API 等)
- 决策(Decision / Reasoning)
- 分析问题、制定计划
- 行动(Action)
- 执行任务(调用工具、写代码、发邮件等)
- 目标导向(Goal-oriented)
- 所有行为围绕“完成目标”
重点不在于“能不能做某个动作”,而在于“能不能为了完成目标,把这些动作组织起来”。
在这方面,后来影响很大的一种范式是 **ReAct(由谷歌的研究人员姚顺雨在 2022 年发布:**https://research.google/blog/react-synergizing-reasoning-and-acting-in-language-models/**)**。
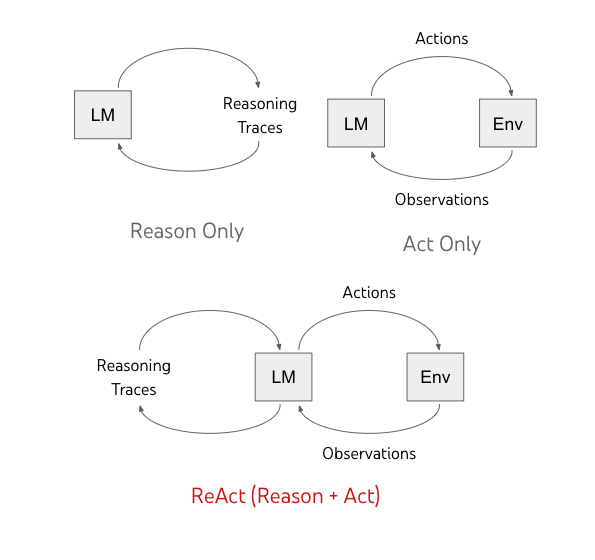
ReAct 这个名字很好理解:Reason + Act,一边推理,一边行动。
还记得 DeepSeek 最开始爆火的时候吗?他们便是早期把 ReAct 过程给公开的产品之一,将“可见的思考过程”让普通用户第一次很直观地感受到“它真的在想”
它强调的不是“先把所有步骤想完再一次性执行”,而是模型在处理任务时进入一个循环:
想想现在该做什么 → 采取一个动作 → 看看动作返回了什么结果 → 再决定下一步做什么。
还是以天气为例:
如果只是普通的 tool calling,流程可能是固定的:用户问天气,模型调用天气工具,然后回答。
但在更偏 Agent 的方式里,内部更像是在经历一个过程:
先判断用户问的是哪个城市;
如果信息不够,就先补齐位置;
拿到位置后,再去调用天气 API;
看到结果后,再决定是只回答天气,还是顺带补一句“明天有雨,出门记得带伞”。
也就是说,ReAct 真正重要的不是让模型“会用工具”,而是把“思考”和“行动”串成一个连续过程。
如果你对这个代码的实现感兴趣的话,可以看看 Claude Code 的实现,在之前泄露的源码里的 src/query.ts,query.ts 是 Claude Code Agent 循环的核心引擎,实现了工具调用的迭代驱动逻辑,其中 queryLoop() 中的 while (true) 就是 Agent 循环的主体,实现了经典的 ReAct 模式,循环的大致逻辑如下:模型生成 → 检测工具调用 → 执行工具 → 结果注入 → 再次调用模型 → …
这是单个用户 Turn 内的 Agent 循环:模型可以连续调用多个工具,每轮工具结果都追加到消息历史,直到模型不再发出工具调用为止
// needsFollowUp = true 时继续循环(有工具调用)
// needsFollowUp = false 时退出循环(纯文本回复)
let needsFollowUp = false
...
// 工具执行
const toolUpdates = streamingToolExecutor
? streamingToolExecutor.getRemainingResults()
: runTools(toolUseBlocks, assistantMessages, canUseTool, toolUseContext)
...
// 状态推进 → 继续下一轮
state = next
} // while (true)
状态管理
Claude Code 之所以需要状态管理,是因为它不是一次性回答问题的聊天机器人,而是一个会跨多步调用工具、读写代码、跑测试、回滚、继续执行的 agent。
这种系统如果没有状态管理,很容易出现三类问题:
- 不知道自己做到哪一步了;
- 上下文越来越长,成本和错误率一起上升;
- 工具调用、副作用和 UI 展示无法保持一致。
Anthropic 在官方工程文章里明确提到,长时运行 agent 不能只靠上下文压缩,还需要让 agent 把进展写入 progress file、把代码提交到 git、并把环境恢复到“clean state”,否则后续 session 会花很多时间“猜之前发生了什么”
Claude Code 的状态管理,核心其实就一句话:它把不同类型的状态分开管理了。 会话本身的内容,比如消息历史、上下文、用量这些,由 QueryEngine 统一维护;当前这轮任务是不是正在执行、能不能中断,则由 REPL 这一层去管理;而真正的模型推理和工具调用过程,再交给 query.ts 里的执行循环去推进。这样做的好处是,聊天记录、运行状态和执行过程不会混在一起,整个系统会更稳定,也更容易恢复。源码里也能看出来,QueryEngine 负责的是一个 conversation 的 lifecycle 和 session state,所以它更像整个会话的“总调度器”,而不只是一个简单的模型调用入口
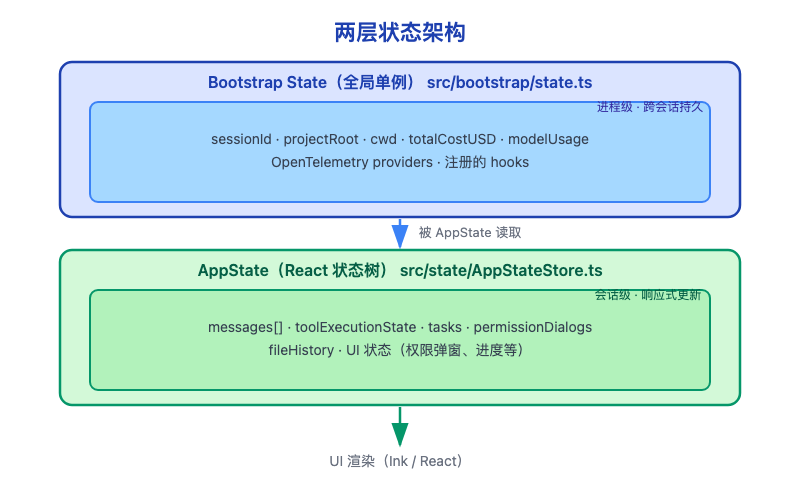
Bootstrap State 是全局的,AppState 是会话局部的。这个边界划分很清晰:跨会话的信息放全局,会话内的信息放局部
可以把 Claude Code 理解成一个“边思考、边调用工具、边把过程输出出来”的编程代理。它不会在收到问题后一次性给出完整答案,而是先生成一部分文本,然后可能发起工具调用,再根据工具结果继续生成后续内容;这一循环会持续进行,直到模型判断任务已完成。官方文档表明,Claude Code 对应的 Agent SDK 内置了这种 Agent 循环和上下文管理能力。
所谓“流式处理”,本质上是把模型的生成过程拆成一个个增量事件并实时发送出来。Anthropic 的文档显示,这些事件既可以是文本增量,也可以是工具参数的 JSON 增量。因此,用户看到的不只是“字一个个冒出来”,而是由“文本、工具调用和执行状态”共同构成的实时工作流。
Context Engineering
个人认为,现在的 AI Agent,最核心的就是 Context Engineering。你可以把 Claude Code 当做一个很会写代码的实习生,但这个实习生现在有一个问题,他脑子里的“短期记忆”非常有限。你如果想让这个“实习生”干活的时候,能够记住你说的内容,不会反复出现幻觉,你需要做的不是让他的脑子更聪明,而是解决:
什么该记住,什么可以先暂时忘记,什么可以先记录在笔记本里,需要的时候再翻找出来
这就是 Context Engineering,官方也有详细的介绍:https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
大模型就像一个很聪明但短期记忆有限的工程师,真正能够决定它能不能够持续写代码、跑长任务的,不是 prompt 写的有多厉害,而是你每一轮应该给他看什么,不该给他看什么,那些需要先存着,哪些需要先压缩,要让他学会“管理资料”。举个例子,当你去询问 CC 这个代码仓库是做什么的,它并不会一股脑地将整个代码仓库全部塞进上下文里,这样很快就爆掉了(很多信息还用不上),它就会和你新上手一个项目一样,先看看项目说明,再根据你的描述去搜一下相关文件,了解项目结构。
其次就是压缩,CC 并不会将所有的聊天过程都一股脑地塞进去,它只会选择有用的内容。比如当对话快接近上下文窗口上限时,Claude Code 会把整段消息历史交给模型,让模型把最关键的信息压成一份高保真摘要,重点保留“架构决策、未解决 bug、实现细节”,同时丢掉“重复的工具输出和冗余消息”;压完以后,不是带着原始长历史继续跑,而是用“摘要后的新上下文”重新开始,并额外带上最近访问过的 5 个文件,并不是简单地把聊天记录缩短一些
Memory
Claude Code 里的 memory,本质上不是“让模型多记一点”这么简单,而是把“记忆”从模型脑子里搬到了文件系统里。 Anthropic 官方把 context engineering 定义成“在每次推理时,持续策划和维护最优 token 集合”的工作,重点不是把更多信息塞进上下文,而是把真正有价值的信息以合适的形式、在合适的时机重新拿回来。也正因为这样,memory 在 Claude Code 里不是一个附属小功能,而是整个长时任务能力的核心部件之一:它负责把那些不适合一直占上下文、但以后又很可能有用的信息,存成外部记忆,再在需要的时候精确召回
还是用之前的实习生的例子,对于一个实习生来说,这个 memory 就相当于是他随身携带的一个笔记本,注意这个笔记本和 CLAUDE.md 还不一样(CLAUDE.md 相当于是它的说明书,有哪些限制,干嘛的,怎么跑,怎么测的),memory 在这里像他的一个经验库,在工作中,ld 告诉他,你要知道这里必须使用 img-box.vue 组件,而不是 imgbox.vue 组件,两个组件的功能不一样哦这种话,并不是只依靠代码就知道的,而是在业务中积累出来的经验,单独记忆。Claude Code 的 memory 不是数据库,不是向量库,甚至不是那种很花哨的“知识图谱”,它首先就是一套文件,存放在 ~/.claude/projects/<sanitized-git-root>/memory/,里面有一个 MEMORY.md 作为入口索引,还有若干真正承载记忆内容的 Markdown 文件。
https://github.com/claude-code-best/claude-code/blob/main/docs/context/project-memory.mdx
系统把记忆约束成一个四类型的封闭分类法:user、feedback、project、reference。这里最漂亮的设计约束是:只记那些无法从当前项目状态实时推导出来的信息。像组件目录结构、路由配置、接口调用方式、构建脚本这些内容,Claude 完全可以现查,不值得消耗记忆预算;真正值得存下来的,是那些代码里看不出来、但后续实现时又很可能影响判断的东西,比如团队约定、设计背景、性能目标、兼容性要求和历史决策。
| 类型 | 存储内容 | 典型触发 |
|---|---|---|
| user | 用户角色、偏好、技术背景 | “我是前端开发”、“我主要写 React 和 TypeScript”、“我更关注性能和可维护性” |
| feedback | 用户对 AI 行为的纠正和确认 | “不要随便引入新组件库”、“改动尽量贴合现有代码风格”、“优先写 hooks,不要改成 class component” |
| project | 非代码可推导的项目上下文 | “这个项目还在用旧版路由方案”、“设计系统下个月要统一升级”、“首屏性能是当前阶段的核心指标” |
| reference | 外部系统指针 | “埋点规范在内部文档里”、“某个 UI 问题要去 Figma 看最新稿子”、“这类兼容性 bug 在某个 issue 里持续跟进” |
Auto-Compact
Auto-Compact 不是在“缩短聊天记录”,而是在“把长对话重新整理成一份可继续执行的工程状态”
你可以把它理解成 Claude Code 的自动“收拾桌面”机制。平时它一边聊天、一边读文件、一边跑命令,桌面上会越来越乱:有聊天记录、有几千行终端输出、有大段文件内容、有各种中间结论。如果这些内容一直原样塞在上下文里,很快就会撞到 token 上限,后面的推理质量也会越来越差。所以 Auto-Compact 做的事,不是简单“删聊天记录”,而是当上下文快满的时候,自动把前面的过程整理成一个更高密度的新版本,让 Claude 还能带着关键状态继续干活。Anthropic 官方对 Claude Code 的描述也是这个方向:当历史变长,它会把消息压成高保真摘要,保留架构决策、未解决问题和实现细节,而不是原封不动背着整段历史继续跑
值得注意的一点是,平时说的 200K 上下文并不是全都可以让我们使用的,我们动态可用的可能就只有 160~180K
200K 总上下文
├── 固定开销 (~15-20K)
│ ├── 系统指令: ~2K
│ ├── 所有启用的 Skill 描述符: ~1-5K
│ ├── MCP Server 工具定义: ~10-20K ← 最大隐形杀手
│ └── LSP 状态: ~2-5K
│
├── 半固定 (~5-10K)
│ ├── CLAUDE.md: ~2-5K
│ └── Memory: ~1-2K
│
└── 动态可用 (~160-180K)
├── 对话历史
├── 文件内容
└── 工具调用结果
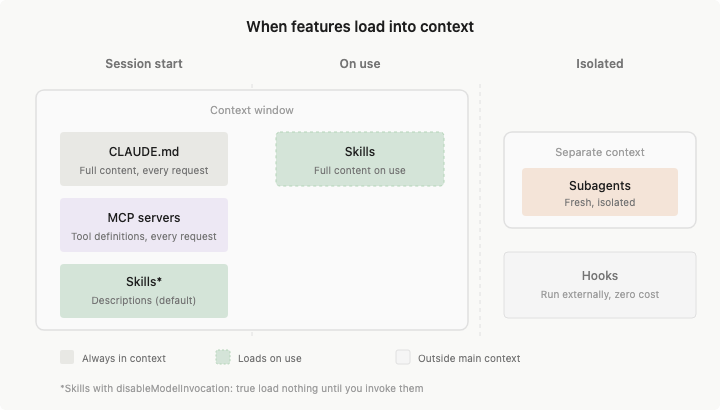
Auto-Compact 顾名思义,是自动触发的,当 token 使用量超过 85% 时显示警告,超过 95% 时强制压缩。这里的触发时机的代码是在:src/services/compact/autoCompact.ts。
压缩的核心思想:用 Claude 自己来总结对话历史